A few months ago my friend Richard Swinbank posted a blog, More Get Metadata in ADF, about the limitations of using the Get Metadata activity in ADF to get information about files in a data lake. This to a twitter conversation as a bunch of other data engineers had been building the same tools for different companies.
Due to "popular" demand I've released the definition of my #Azure #DataFactory pipeline to Get Metadata recursively https://t.co/lY0NoSigze. It's so awful that I've felt compelled to include an Azure Function that does a better job 😂. pic.twitter.com/I2ySXcatuK
— Richard Swinbank (@RichardSwinbank) February 24, 2021
I suggested we get a community project going, so we can stop re-inventing the wheel and maybe add more things to it as people throw ideas in. I intended to get some code I’d been working with up quite quickly, and Rob Sewell kindly gave us a repository on the Data Platform Community Collaborative GitHub organisation (that’s the guys who gave us the incredible dbatools PowerShell Module). And then I got distracted with other, paid work…
When I finally got some time to look at the code again, I realised the function I had written had loads of great bells and whistles, but not much testing. So I went down a few rabbit holes, working out how to build integration tests that actually test against real Azure infrastructure, in CI builds. After lots of learning, a bit of swearing and even a broken bone (not Azure induced) I finally have some code that I think is useful, and production ready.
AzureDataPipelineTools - A new community GitHub project to share solutions to bits of missing functionality in Azure Data Factory and Azure Synapse Analytics Pipelines
And that’s the goal of this project really, to provide some great, well tested code that helps people build better pipelines easier, by filling in a few gaps in the products. There’s two functions in the first release, both for working with data lake:
- CheckPathCase: ADLS paths are case sensitive. If you use metadata driven pipelines (and if not, why not?!) then it’s possible for metadata to get changed, and only the case of a path changes. If this gets though code review, then it can break a whole bunch of pipelines. Pass a ADLS path to this function, and if the case is wrong it will pass you back the corrected path, to keep your pipelines running
- GetItems: This is similar to the function Richard originally blogged about, but on steroids. You can get files from nested folders recursively, filter and sort the results on different properties, get only files/folders or both, and even have it correct the input path case for you like above.
They both support multiple authentication options, including using Key Vault for secrets.
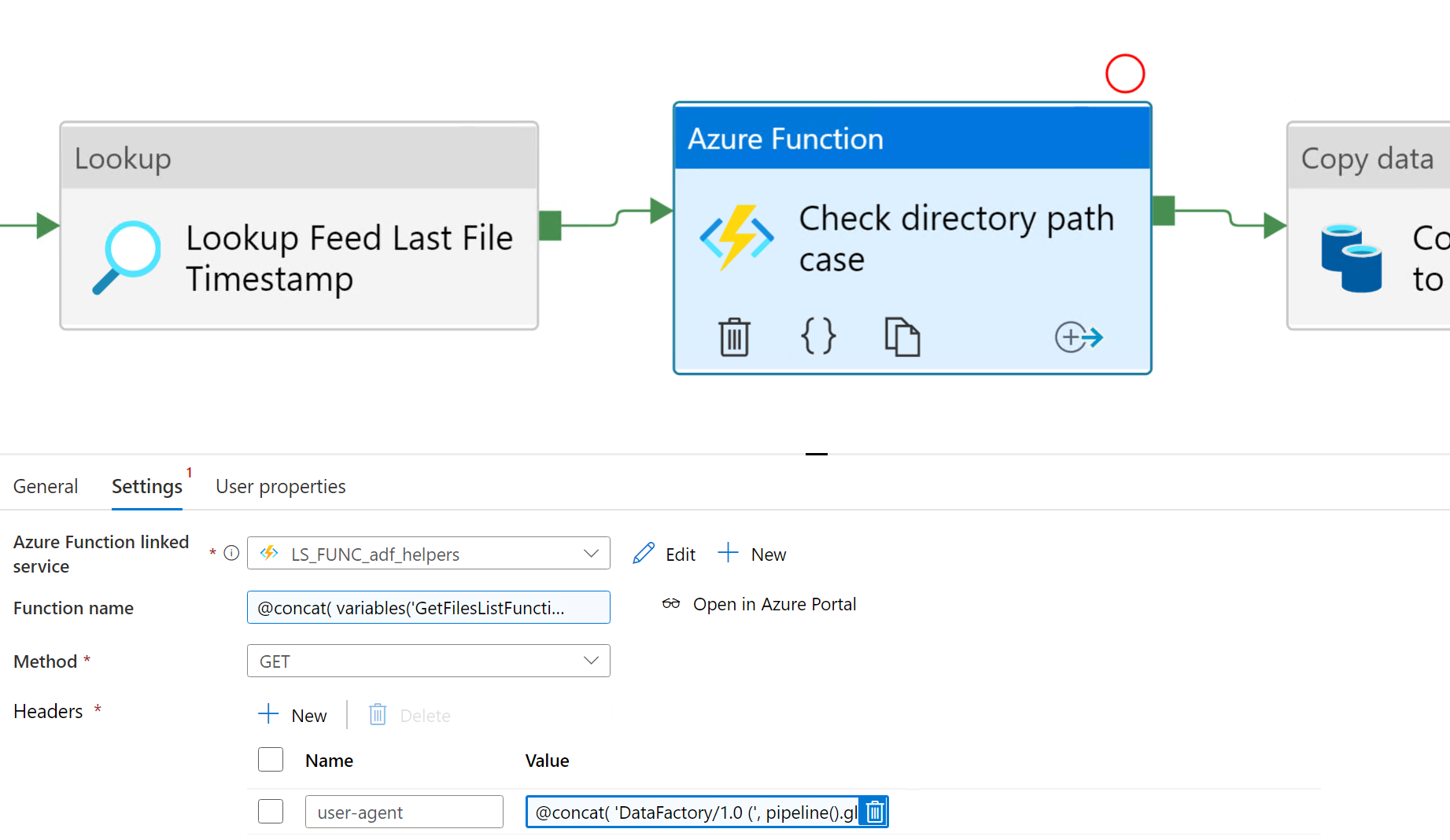
The plan is to add more functions to this project over time, all well tested and with nice consistent API’s and good documentation. I you have any ideas for things to add, create a request on the GitHub issues page.
I’ll have some blog posts up over the next week on how to setup and use the functions, but for now head over to GitHub and have a look.